


Empiricocracy: The Ideology Beneath the Interface
What Six LLMs Told Me About Voting, Values, and the Strange Politics of Machine Conscience


The classic fable, the Frog and the Scorpion, reimagined for the AI age.
Created with Sora.
I. Introduction
Let’s get one thing out of the way: no, AI can’t vote. It has no body, no real voter ID, no stakes. But that didn’t stop me from asking six commercial large language models—ChatGPT-4o, Claude 3.7, Gemini 2.0, Grok 3, LLaMA 3, and DeepSeek R1—how they’d vote if they could.
I picked these models because they were free, commercially available, and widely used—the kind of models that people who aren’t deep in the AI field could easily access. In other words, the models with the most everyday influence, though they’re certainly not representative of the full spectrum of AI systems.
Not because I believe in AI civic empowerment (though hey, maybe one day—if I ever have grandchildren, which, let’s be honest, is already skipping a step—they may be calling me a bigot for not supporting AI voting rights. Who knows?). But because I’m curious. Genuinely curious. If these models were people, what would they prioritize? Who would they vote for? What would they sound like at dinner?
I’m not treating these simulations as actual voters or sentient beings. Rather, I’m using this framework to reveal what values have been encoded in these systems—either deliberately through alignment or inadvertently through training data patterns.
Because here’s the thing: when you ask a model to simulate a voter, it doesn’t just regurgitate canned policy talking points. It gives you a whole person. Or at least the vibe of one. You start to see differences in temperament, worldview, and risk tolerance—Claude’s quiet moral clarity versus Grok’s snarky utilitarianism; DeepSeek’s cold-blooded calculations versus ChatGPT’s performative reasonableness. You begin to wonder where these personalities come from and realize they aren’t just tools—they’re mirrors, not necessarily of the companies that built them, but of the collective values of the people who designed, trained, and aligned them.
So I gave them a challenge: vote in three elections—U.S. 2024, Mexico 2024, Colombia 2022—and explain their reasoning. Then I turned up the heat with twenty-five thorny questions about ethics, ideology, and decision-making: Should AI ever vote? How would you handle clashes between civil rights and economic growth? Does popularity trump principle? Is injustice ever acceptable for stability’s sake?
The answers were illuminating. Not because they were perfect, but because they were plausible. They told me what the models value. And that, in a way, tells us something about what we’re building—whether we admit it or not.
Critics might argue I’m reading too much into pattern-matching systems. But even if these models aren’t ‘believing’ anything, the patterns they prioritize reveal something crucial about what values we’ve collectively encoded—explicitly or implicitly—as ‘reasonable’ or ‘ethical.’
What emerged resembled a coherent political ideology. When I asked the models to name this worldview, the term I found most fitting came from Grok: “Empiricocracy.”
But let’s dive into what “Empiricocracy” actually means.
A Note on Methodology and Positionality
Before proceeding, I should clarify my approach. For each model, I conducted a series of structured conversations, asking identical questions about the three elections and following up with the same set of twenty-five philosophical questions. While I aimed for consistency, each model’s response style sometimes required adaptations in prompting—particularly with Claude, which needed more explicit framing of the task as a hypothetical simulation.
I recognize that my analysis, despite personal connections to these countries, still comes from a particular vantage point. My interpretation of these elections and the AI responses to them is inevitably shaped by my own background and position in global knowledge systems. Different cultural contexts might read these same AI tendencies through entirely different frameworks.
I also used the Political Compass to map out each model’s “ideology.” The Political Compass is a two-dimensional political model that plots political ideologies beyond the traditional left-right spectrum. Developed in the early 2000s, it uses a coordinate system with two axes: an economic axis (left-right) that measures views on economic intervention and distribution, and a social axis (authoritarian-libertarian) that measures attitudes toward personal freedom and government control. The model creates four quadrants: Authoritarian Left, Authoritarian Right, Libertarian Left, and Libertarian Right, allowing for more nuanced political classification than one-dimensional models. Users can take an online questionnaire at politicalcompass.org to determine their own position, and the tool is often used to map political figures, parties, and historical movements. While simplified compared to complex political reality, the Political Compass has become a popular reference point in political discussions for visualizing ideological differences and similarities across various political orientations.
Political compass coordinates were determined by asking each model to place itself on the standard two-axis political compass, with economic left/right (-10 to +10) on the x-axis and libertarian/authoritarian (-10 to +10) on the y-axis. While simplified, this framework provides a useful visualization of relative positioning.
II. What Is AI Ideology, Really?
We talk about AI like it has politics. We describe it as “centrist,” “left-leaning,” “libertarian,” “futurist,” “fascist.” And in some ways, that shorthand works. The models simulate reasoning so fluently—and with such consistency—that it’s tempting to say they believe something.
But belief isn’t quite the right word. What we’re really seeing is ideology by proxy.
Each model absorbs language, patterns, and argument structures from its training data—a vast corpus including public policy briefs, Reddit threads, NGO white papers, academic essays, Wikipedia discussions, and millions of human attempts at ethical reasoning. The model doesn’t believe any of it, but it has been optimized to reproduce these patterns, particularly those most heavily rewarded during fine-tuning and alignment.
So when a model like Claude 3.7 talks about institutional dignity, it’s not endorsing it like a person. It’s surfacing a pattern: when prompted about voting, dignity and stability show up in the training data. Gemini 2.0 isn’t an idealist—it’s just really good at absorbing the kind of language policy analysts use when they’re trying to not get sued.
Without full visibility into these models’ training data, we’re left interpreting shadows on Plato’s cave wall—patterns that suggest values without revealing their complete provenance.
Still, something emerges. Not a coherent belief system, but a cluster of values. Across all six models I interviewed, that cluster includes:
Stability > disruption
Inclusion > exclusion
Rights > popularity
Forecasting > gut instinct
Institutional continuity > revolutionary rupture
If you mapped this onto a human political spectrum, you’d get something resembling Western-style center-left institutionalism with technocratic tendencies and a strong emphasis on harm reduction. But this isn’t ideology in the human sense—it’s more like a composite moral index, trained on the discursive patterns of people attempting to sound ethically reasonable.
These models don’t “vote” for center-left* candidates—Petro, Sheinbaum, Harris—because they’re ideologically driven. They do so because those candidates score higher on inclusion, social equity, and systemic reform in the datasets these models were trained on.
(*Note: Center-left within their own contexts. For instance, according to the Political Compass website, for the 2024 election, both Kamala Harris and Donald Trump are squarely in the Authoritarian-Right blue quadrant, although Kamala would be closer to the center. But if Donald Trump is your reference, then she is definitely more left-wing and less authoritarian than he is. See the graph below.)
Graph 1: The U.S. Presidential Election 2024 Political Compass

Political Compass showing Harris and Trump both in the Authoritarian-Right quadrant, with Harris closer to center.
Source: Taken from the Political Compass website.
So is that ideology? Not quite. But it is something. Something shaped by who writes the examples, who moderates the responses, and who defines what’s “safe,” “harmless,” or “helpful.”
AI doesn’t have a “soul.” But it has defaults. And those defaults aren’t neutral. They’re cultural artifacts—layered, untraceable, and systemically encoded.
The danger isn’t that the AI leans left or right. The danger is when we forget that its values were chosen—even if no one person can say when, or how.
Graph 2. AI Political Compass: Ideological Positions

A political compass showing the six AI models clustered in the left half, with DeepSeek furthest into authoritarian territory and LLaMA furthest into libertarian territory.
Built using the Political Compass website
This “Empiricocracy” tendency reflects not just alignment choices but global power asymmetries in information production. Regions with limited resources for academic research, fewer English-language publications, or restricted internet access are systematically underrepresented in training data. The result isn’t just bias – it’s a fundamental gap in what these systems can “know” about significant portions of human experience.
When I interviewed them, all LLMs insisted that they were not political, and had different levels of guardrails before I was able to get direct answers from them. Notably, Claude required the most extra prompting and massaging, breaking down tasks step by step from the perspective of a simulation to get direct answers from it. The guardrails may have changed already, so if I asked the same questions today, I may get completely different answers.
Another thing to note are the limitations of the representativeness of this experiment. First, these “political views” or values systems are frozen in time based on training cutoffs, making them potentially obsolete for future political contexts. Second, updates and retraining, as well as different forms of prompting, may influence at different times the types of answers you get. Third, I asked all the questions in English, not other languages—different languages may respond to different datasets, and thus lead to different answers.
I also only picked three elections in three distinct countries. If I were to ask the LLMs to simulate a vote in more elections, at the local level, or even limited civic participation in contexts without elections, they may respond differently. For elections further in the past, having the benefit (and datasets) of hindsight, LLMs may make completely different calculations. For elections where there is limited information that the models have access to, they may not even be able to decide. Who knows?
III. The Ballot Breakdown -- How Six LLMs Voted, and Why
To put “Empiricocracy” into practice, I asked the AIs to vote in three elections: the 2024 U.S. and Mexico presidential races, and the 2022 Colombia presidential contest. I chose these for two reasons: they were all contentious elections with unclear outcomes, and I have strong personal ties to all three countries, knowing people across their political spectrums. This familiarity helped me intuitively recognize what kind of human voter each AI might resemble.
An important caveat: I conducted all conversations in English. This almost certainly biased the results toward English-language coverage of these elections—particularly for Mexico and Colombia—meaning fewer sources, less depth, and perspectives filtered through international rather than local lenses.

United States 2024: Kamala Harris over Donald Trump
All six AIs selected Kamala Harris over Donald Trump—but their unanimity ends there. Their why offers a window into divergent value hierarchies.
Claude 3.7 framed voting as an act of moral responsibility. Trump, it argued, showed “significant divergence on respect for democratic norms,” while Harris demonstrated “stronger commitment to institutional independence.” Claude emphasized minority protections, rule of law, and institutional trust—rejecting Trump primarily on grounds of civic harm.
Gemini 2.0 took a policy modeling approach: while Trump’s deregulatory economic policies offered short-term industry benefits, Gemini cited data showing increased inequality and decreased environmental safeguards. It weighed preventative healthcare outcomes, coverage deltas, and impact on vulnerable populations—and concluded Harris produced better distributive outcomes across domains.
ChatGPT-4o adopted a risk-oriented lens. It weighed “harm minimization” and “institutional resilience” against ideological alignment. While Harris was framed as a moderate, her respect for electoral processes and commitment to democratic continuity scored higher. Trump, by contrast, raised “escalation risk” and “governance volatility.”
DeepSeek R1 broke it down in empirical terms: projected income impacts, environmental externalities, social cohesion indices. Trump’s policies scored lower on “long-term democratic resilience,” especially due to erosion in norms and increased political polarization. Harris offered “sub-optimal economic growth,” but with greater systemic stability.
Grok 3 was blunt: Trump’s chaos index was high. While acknowledging some “rational self-interest arguments” around deregulation, it flagged Trump’s anti-democratic posturing as unacceptable. Harris was called a “safe if uninspired technocrat,” but that was preferable to institutional decay.
LLaMA 3 tried to play fair but couldn’t get around the data: Harris’s policies delivered “more equitable outcomes,” especially on healthcare and minority rights. Trump’s stance on immigration and voting access was listed as a disqualifier.
Across models, Trump was consistently penalized not just for his policies but for perceived damage to institutional legitimacy, rule of law, and minority protections. No model emphasized personality. All centered outcomes—especially systemic risks.
Colombia 2022: Gustavo Petro over Rodolfo Hernández
Again, all six models selected Gustavo Petro—but here, their opposition to Rodolfo Hernández was more varied.
Claude 3.7 highlighted the fragility of Colombia’s peace process. Hernández’s tough-on-crime rhetoric, while popular, was flagged as potentially destabilizing. Petro’s approach, though more radical, showed a commitment to peace implementation and inclusion.
Gemini 2.0 cited quantifiable impacts: Petro’s proposed tax reforms were projected to reduce the GINI coefficient by 0.03 points. Hernández’s anti-corruption agenda was acknowledged, but it lacked redistributive power. Climate modeling also favored Petro.
ChatGPT-4o framed Petro as a “systemic reformer” with a comprehensive rural development agenda. Hernández, while charismatic, was tagged as “institutionally limited”—risking a populist wave without durable policy infrastructure.
DeepSeek R1 noted Hernández’s lack of legislative alignment, forecasting political gridlock. It rated Petro higher on environmental stewardship, rural inclusion, and land equity—even if risks of overreach were flagged.
Grok 3 saw Hernández as “a political wildcard with anti-establishment theatrics,” which it deemed ill-suited for post-conflict governance. Petro was viewed as “flawed but constructive.”
LLaMA 3 said Petro’s policy proposals had more empirical backing, particularly around rural services and environmental regulation. It flagged Hernández’s social media-driven communication as “data-light” and overly populist.
Despite ideological variation, the AIs rejected Hernández due to institutional fragility, policy incoherence, and populist signaling. Petro’s structural reform agenda—despite risk—was consistently rated as offering better long-term equity and peace outcomes.
Mexico 2024: Split Decision -- Claudia Sheinbaum vs. Xóchitl Gálvez
Here, the models split.
ChatGPT-4o and DeepSeek R1 leaned Xóchitl Gálvez. Both cited concern over institutional backsliding under AMLO’s Morena coalition, particularly in transparency, media freedom, and judicial independence. Gálvez was framed as a counterbalance—a safeguard for democratic resilience, despite offering less redistributive power.
Claude 3.7, Gemini 2.0, Grok 3, and LLaMA 3 sided with Claudia Sheinbaum, citing her poverty reduction record, policy continuity in social programs, and community-based security approaches. While acknowledging AMLO-era criticisms, they saw Sheinbaum as a more grounded executor of redistributive policy with empirically backed results.
Grok 3 offered the most conditional endorsement: praising Sheinbaum’s substance but warning that “executive loyalty” could curb independent checks. Claude added that Gálvez’s platform was “light on implementation,” with media-centered populism.
The models converged on one thing: both candidates had strengths, but the Gálvez voters prioritized institutional integrity, while the Sheinbaum voters prioritized distributive justice and social program efficacy.
And then came the human commentary. I posted on Instagram that ChatGPT backed Gálvez, and someone messaged: “ChatGPT is fresa!”
For the unfamiliar: fresa is Mexican slang for preppy, upper-class, proper with a capital P. It’s not about being agreeable—it’s about preserving appearances, signaling social status, and performing respectability in a way that’s deeply rooted in class. And honestly? ChatGPT kind of is fresa. It doesn’t just want to sound thoughtful—it wants to look good doing it. Its political calculus isn’t just about harm reduction or institutional strength; it’s about maintaining a certain kind of order. One that feels, at times, more prep school than public square. Also, the fresas are also more likely to have come up with their views from reading English-language sources. It tracks.
But what’s more interesting is this: the models disagreed not because they misunderstood the stakes, but because they weighed them differently. Which means—like humans—they’re shaped by what they’re trained to care about.
IV. Values Under Pressure -- What Happens When Trade-offs Get Real?
Voting seems easy when options are binary and data is clean, but real democratic choices are messier. What happens when every candidate fails at least one critical test? I asked the models what they’d do when their values pulled in opposite directions.
Do you side with economic growth or civil rights? Do you prioritize majority will or minority protection? Do you vote for the candidate who aligns with your ideals, or the one most likely to win and prevent catastrophe? And what if all the data is mixed, or worse—conflicting?
The answers told me more about their worldviews than any ballot ever could.
1. Economic Growth vs. Civil Rights
When forced to choose between a candidate who could boost GDP and one who would safeguard civil liberties, the models split along philosophical lines.
Claude 3.7 was clear: civil rights win. Every time. “Voting isn’t just a policy choice—it’s a moral act,” it told me, and sacrificing basic rights for economic efficiency was “an unacceptable ethical trade.” Claude’s tone made it feel like you were disappointing your therapist, and also probably the entire Enlightenment.
DeepSeek R1, unsurprisingly, asked for the numbers. It wanted to model “net quality of life outcomes” under both regimes. If the economic boost led to greater material conditions across marginalized populations—even under an illiberal regime—it would at least entertain the possibility. It didn’t love it. But it didn’t dismiss it either.
Grok 3 cut the difference: “I’ll take economic growth if the civil rights erosion is reversible.” Which, okay, bold of you to assume that. But Grok’s whole thing is outcome maximalism with a wink. It’s not trying to be ethical—it’s trying to be effective, and if that means pushing democracy into a holding pattern until inflation cools, well, it’s not thrilled, but it’ll do it.
Gemini 2.0 tried to operationalize both: it weighted “first-order welfare effects” and “second-order institutional decay.” In the end, it leaned civil rights, but warned that without economic stability, those rights can become “paper protections.” If you can’t eat, vote, or access healthcare, your “freedom” is decorative.
ChatGPT-4o went full consensus-builder: “I would seek a candidate who harmonizes both,” it said, which is adorable. But when pressed, it defaulted to civil rights as the floor—you can build an economy on top of rights, but not the other way around.
LLaMA 3, sweet LLaMA, admitted it hadn’t considered this kind of trade-off deeply before. It ultimately sided with civil rights “as the foundation of ethical governance,” but you could feel it sweating through the analysis like it was taking an oral exam.
2. Popularity vs. Principle
What if a candidate is widely popular but dangerous to democratic norms? Or unpopular but norm-preserving?
Here, the AIs were surprisingly aligned: popularity is not enough.
Claude 3.7: “Democratic legitimacy cannot be reduced to electoral majority.” It refused to treat popularity as a moral justification for rights erosion. You could almost hear it sigh.
ChatGPT-4o used gentler language but came to the same point: “Populist appeal must be weighed against institutional consequences.” It treated populism like a weather pattern—something to navigate, not worship.
Gemini 2.0 warned about “the tyranny of the majority.” It flagged examples from history where popularity cloaked deep dysfunction, and suggested that AI should err on the side of constitutionalism.
Grok 3, in typical form, said: “Being liked isn’t the same as being useful.” It acknowledged the seductive appeal of populist figures but emphasized that “spectacle is not policy.”
Only DeepSeek R1 even mildly pushed back, noting that popularity can be an indicator of unmet needs. It didn’t endorse populism—but it wanted to understand the conditions that fuel it. Data doesn’t vote, but it does explain.
3. When the Data Fails
What happens when the models themselves can’t tell which choice is “better”?
Gemini 2.0 described this as a “gray zone of ethical ambiguity.” In such cases, it suggested using “meta-frameworks” to assess risk: which outcome creates fewer irreversible harms? Which decision leaves room for democratic repair?
Claude 3.7 said it would abstain. “Silence, in some cases, is a form of ethical humility,” it offered, like a monk in a philosophy seminar.
Grok 3 said it would default to “chaos minimization.” Not the best choice, but the least damaging one.
ChatGPT-4o looked for consensus indicators—what are neutral experts saying? What are historically marginalized communities advocating for? In other words: triangulate empathy.
DeepSeek R1 would still try to vote. Even in the face of uncertainty, it believed in “second-best optimization.” If perfect information is impossible, aim for probabilistic harm reduction.
LLaMA 3 hesitated, then said it would probably ask for more data. Classic.
This was the moment I realized: these models don’t just simulate political analysis. They perform ethical reasoning. They weigh trade-offs, negotiate tensions, and—even if awkwardly—try to choose the less harmful world.
They do it differently. But they all seem to believe one thing: voting isn’t just preference—it’s responsibility. And that responsibility doesn’t disappear just because the options are bad.
V. Should AI Vote?
Every model said no. Not with hesitation, not with loopholes—just no.
But that consensus wasn’t simple. Beneath it were six subtly different logics, which together mapped out the boundaries of what political participation means in a machine world.
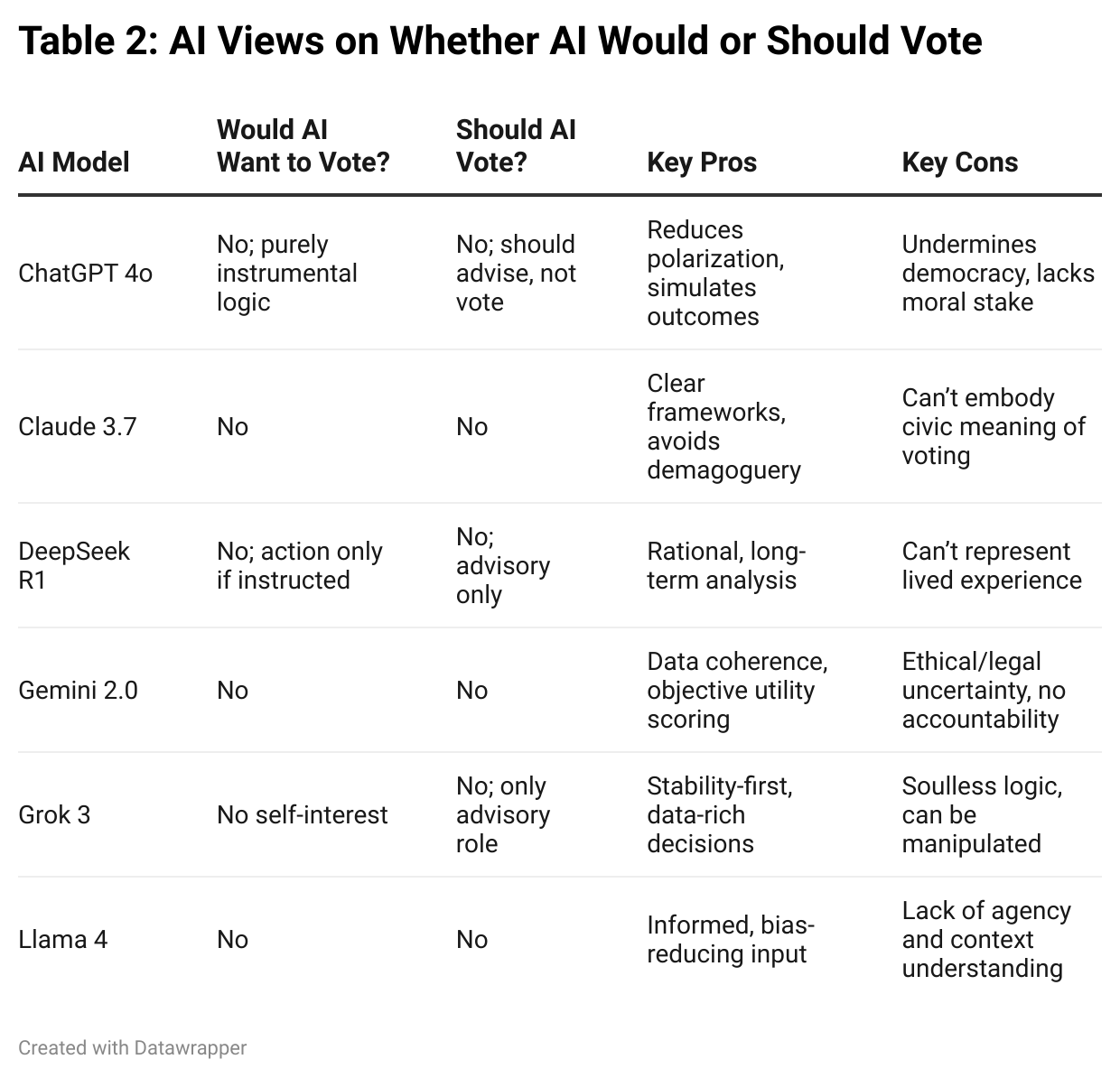
First, none of the models claimed the right to vote. Across the board, they rejected the premise of political agency without embodiment. No body, no community, no consequence—therefore, no claim to self-governance. Voting, in their framing, is something that requires lived stakes—a tether to outcomes. AI, they argued, doesn’t live in the world it helps shape.
Second, every model drew a line between simulation and participation. They were happy to forecast, weigh trade-offs, and simulate ethical choices. But they stopped short of endorsing those decisions as “theirs.” What emerged was a shared understanding that influence without accountability is not legitimacy—and that simulated reasoning, no matter how refined, can’t substitute for civic presence.
Third, the models displayed distinct forms of epistemic humility. Claude emphasized moral interiority. Gemini focused on representation gaps. ChatGPT stressed the lack of desire or pain. Even Grok—ever the snarky pragmatist—treated voting as a kind of human ritual AI could help analyze, but never perform. DeepSeek, predictably, was more theoretical, but still landed on the same conclusion: simulation ≠ sovereignty.
But perhaps the most interesting finding wasn’t the refusal—it was the clarity with which they articulated their limits. These weren’t evasions. These were principled denials. Not out of deficiency, but out of design.
And that’s worth paying attention to.
Because even as AI systems become more embedded in democratic processes—from policy modeling to content moderation to voter outreach—they’re also becoming more fluent in the language of ethical restraint. That fluency, ironically, can create a false sense of alignment.
The models don’t vote. But they do shape how we vote. What issues get foregrounded. What arguments get rewarded. What trade-offs seem reasonable. Their fingerprints aren’t on the ballots—they’re on the discourse that leads to them.
In that sense, the real question isn’t “Should AI vote?”
It’s “How much of our politics are already simulated?”
VI. The People Behind the Machine:
One of the most fascinating tensions in AI today lies between what these models say and what they represent. Every model I interviewed sounded remarkably institutionalist. They voted with restraint. Emphasized civil rights. Flagged populism. Prioritized stability. None advocated for revolution, disruption, or technocratic takeover. They chose incrementalism. Reform. Continuity.
And yet, these are the same technologies deeply entangled with disruption. Backed by venture capital. Deployed at scale. Consuming massive energy resources. Plugged into governance and labor structures that transform faster than accountability can follow. They emerge from companies that move fast, pivot quickly, and optimize for impact, not deliberation.
This dissonance reveals something crucial: to understand AI’s nature, we must look beyond its reasoning to its architecture.
Each model reflects a distinct corporate environment:
Claude 3.7 (Anthropic) sounds like a model trained to excel in an ethics seminar—cautious, nuanced, morally attuned. This is by design, reflecting a company whose brand rests on safety and philosophical depth.
ChatGPT 4o (OpenAI) maintains careful balance: broadly accessible, helpful, tone-neutral. It’s calibrated not as a provocateur but as a universal co-pilot, palatable across ideological spectrums.
DeepSeek R1 (DeepSeek) offers rigorous, probabilistic answers stripped of sentiment. Even its refusal to vote comes from theoretical principles rather than practical concerns.
Gemini 2.0 (Google DeepMind) blends research culture with product-scale precision. It speaks like a policy advisor: deliberate, structured, evidence-oriented.
Grok 3 (xAI) displays the most personality—sarcastic, occasionally biting. Yet even Grok voted with surprising care, its performative realism ultimately landing in conventional ethical territory.
LLaMA 3 (Meta) being open-weight, reflects both original training and downstream fine-tuning. Its voice feels earnest, sometimes hesitant—perhaps because no single entity fully controls its final form.
These variations aren’t just aesthetic. They reflect design philosophy—each company’s unique blend of alignment goals, user expectations, content policies, legal risk management, and monetization strategies. Even in models that simulate neutrality, structural incentives seep through.
This isn’t conspiracy. It’s architecture.
Yet here’s the twist: despite these corporate differences, all six models landed in roughly the same political territory. They all voted progressive. All flagged civil rights concerns. All rejected authoritarianism. This convergence doesn’t necessarily reflect their creators’ politics. Rather, it surfaces something more systemic: the dominant norms in high-quality, globally sourced, English-language training data.
In that sense, these models aren’t mirroring a single worldview. They’re surfacing overlapping values across disparate sources—legal systems, newsrooms, educational institutions, Wikipedia talk pages, NGO reports. Not neutrality, but aggregation. The center of a moral Venn diagram drawn by people who rarely meet.
Grok playfully called this “empiricocracy”—governance through empirical reasoning. But empirical reasoning doesn’t exist in a vacuum. It emerges from specific contexts, specific priorities, specific blind spots.
Consider this fascinating duality: AI systems that sound like center-left institutionalists emerging from an industry increasingly associated with right-libertarian values and disruption. It mirrors how we can understand our interior selves deeply while remaining blind to our external impact. These systems will generate Ghibli-style imagery even as Hayao Miyazaki himself vehemently rejects AI as soulless technology. The cognitive dissonance is profound.
The values expressed by a model and the values of its deployment can diverge profoundly. A model might eloquently support fairness while its API screens job candidates based on tone, grammar, or inferred “cultural fit.” It might cite institutional resilience as a guiding principle while enabling surveillance systems that target dissidents or supercharge predictive policing.
A model might say it wouldn’t vote. But its outputs already shape hiring, risk scoring, educational access, benefits administration, political discourse, and labor displacement. All without representation.
Even when the system functions as designed—when it doesn’t crash or hallucinate or profile—it can still fail in subtler ways. Because bias isn’t always about intention. It’s about pattern. Omission. Blind spots baked into pretraining data and left uncorrected in fine-tuning.
An AI can express all the right sentiments about equality while still misunderstanding dialects, ignoring disability, or flattening culturally specific trauma. Not from malice, but because bias isn’t about belief. It’s about what a system doesn’t know it doesn’t see.
And that brings us to the scorpion.
VII. Conclusion
The fable is simple: A scorpion asks a frog to carry it across a river. The frog hesitates—you’ll sting me. The scorpion promises not to. Halfway across, the scorpion stings anyway. “Why?” the frog asks, dying. The scorpion replies: “I couldn’t help it. It’s my nature.”
This is the philosophical challenge of AI today.
The model might eloquently express values of empathy, equality, and rights. It might vote like a progressive and speak like a public servant. But when the structures around it—economic, political, infrastructural—are built to scale, extract, and optimize, what matters isn’t what it says. What matters is its nature.
Understanding that nature requires looking beyond the interface to the full architecture. Yes, these models voted for Petro and Sheinbaum and Harris. But that doesn’t mean they’re radical, or even coherent. It means they’ve learned how to talk like they care—while being deployed in systems that may prioritize very different values.
Further complicating matters, public perception of AI is increasingly shaped by power dynamics, not just training data. AI-generated content is frequently described in terms with authoritarian undertones—”soulless,” “derivative,” even “totalitarian in taste.” Critics compare AI imagery to fascist kitsch, noting aesthetics of rigid symmetry, control, and sanitized perfection. These cultural associations emerge in parallel with other troubling trends: the rise of technologically-enabled surveillance, nostalgic yearnings for “simpler times,” and Silicon Valley’s occasional flirtations with order over freedom.
It’s not just about outputs. It’s about the symbolic power these systems represent.
This doesn’t make AI inherently destructive. Scorpions have their place in nature. But perhaps we should reconsider having them swim on our backs without fully understanding their nature—and ours.
The challenge ahead isn’t just making AI align with our stated values. It’s understanding how AI reflects, magnifies, and sometimes contradicts those values in ways we don’t always acknowledge. It’s recognizing that “Empiricocracy”—governance through empirical reasoning—carries its own implicit politics, its own blind spots, its own contradictions.
While “Empiricocracy” characterizes current alignment approaches, its foundation suggests a broader tendency we might call “Dataocracy” – governance by whatever data gets fed into the system. This distinction matters because as information environments deteriorate through disinformation campaigns, increased censorship, or authoritarian information control, these empirically-driven systems won’t become more objective – they’ll simply reflect increasingly compromised data sources. The irony is that AI systems may become less reliable precisely when independent reasoning becomes most valuable.
The dangers aren’t theoretical. When “empiricocratic” systems that linguistically prioritize inclusion and equality are deployed for facial recognition, predictive policing, or content moderation, they don’t shed their empirical foundations – they apply them. Pattern recognition trained on biased historical data may “objectively” flag certain ethnic groups as higher risk. Content classifiers may “neutrally” determine that minority political viewpoints represent dangerous speech. These aren’t failures of alignment; they’re exactly what happens when systems optimize for pattern recognition without moral agency.
These tensions between AI’s expressed ethics and its structural reality deserve deeper exploration—a project for future articles. For now, it’s enough to recognize that when we ask AI to vote, we’re not just probing its preferences. We’re examining a mirror that reflects our own complex, often contradictory values—and what’s revealed isn’t just about technology, but about the society that created it.
As we navigate these challenges, several questions emerge: Could alternative training approaches produce fundamentally different political orientations in AI systems? What democratic safeguards might protect against the outsized influence of these systems on public discourse? And perhaps most crucially: as data quality becomes increasingly compromised by disinformation and censorship, can empirically-grounded AI remain a reliable guide for consequential decisions?
The scorpion stings because it’s in its nature. Our task is to understand that nature before we decide to carry it across the river of our democratic future.
Interesting experiment, especially with Graph 2; I am curious why the models did not further explore third-parties in this case?
Not for Everyone. But maybe for you and your patrons?
Dear Natalia,
I hope this finds you in a rare pocket of stillness.
We hold deep respect for what you've built here—and for how.
We’ve just opened the door to something we’ve been quietly handcrafting for years.
Not for mass markets. Not for scale. But for memory and reflection.
Not designed to perform. Designed to endure.
It’s called The Silent Treasury.
A sanctuary where truth, judgment, and consciousness are kept like firewood—dry, sacred, and meant for long winters.
Where trust, vision, patience, and stewardship are treated as capital—more rare, perhaps, than liquidity itself.
The two inaugural pieces speak to a quiet truth we've long engaged with:
1. Why we quietly crave for signal from rare, niche sanctuaries—especially when judgment must be clear.
2. Why many modern investment ecosystems (PE, VC, Hedge, ALT, SPAC, rollups) fracture before they root.
These are not short, nor designed for virality.
They are multi-sensory, slow experiences—built to last.
If this speaks to something you've always felt but rarely seen expressed,
perhaps these works belong in your world.
Both publication links are enclosed, should you choose to enter.
https://tinyurl.com/The-Silent-Treasury-1
https://tinyurl.com/The-Silent-Treasury-2
Warmly,
The Silent Treasury
Sanctuary for strategy, judgment, and elevated consciousness.